An almost fatal data bug
How a data change to the SEC filing indexes broke edgartools and how it was fixed

Sometime Friday night December 20th 2024 someone pushed a change to production. And just like that edgartools broke.
This wasn't a minor impact. The get_filings call - the original function in edgartools that displays the list of available filings just stopped working. There are other ways to get filings of course. If you knew the company, you could still get their filings. But there are so many potential workflows built on getting regular filings that this was an issue.
The root cause
It wasn't hard to figure out the root cause. One of the errors I saw in the failed Github unit tests was ArrowInvalid: Failed to parse string: 'ER 8206' as a scalar of type int32 which pointed to string data being parsed as an int. Given that the code that read the filing index files is 2 years old, it's more likely a data bug than a code bug.
Sure enough it was a data bug. I downloaded an index file for 2020 Q1, searched for the string `'ER 8206'` and found the following misalignment due to the company name being too long.
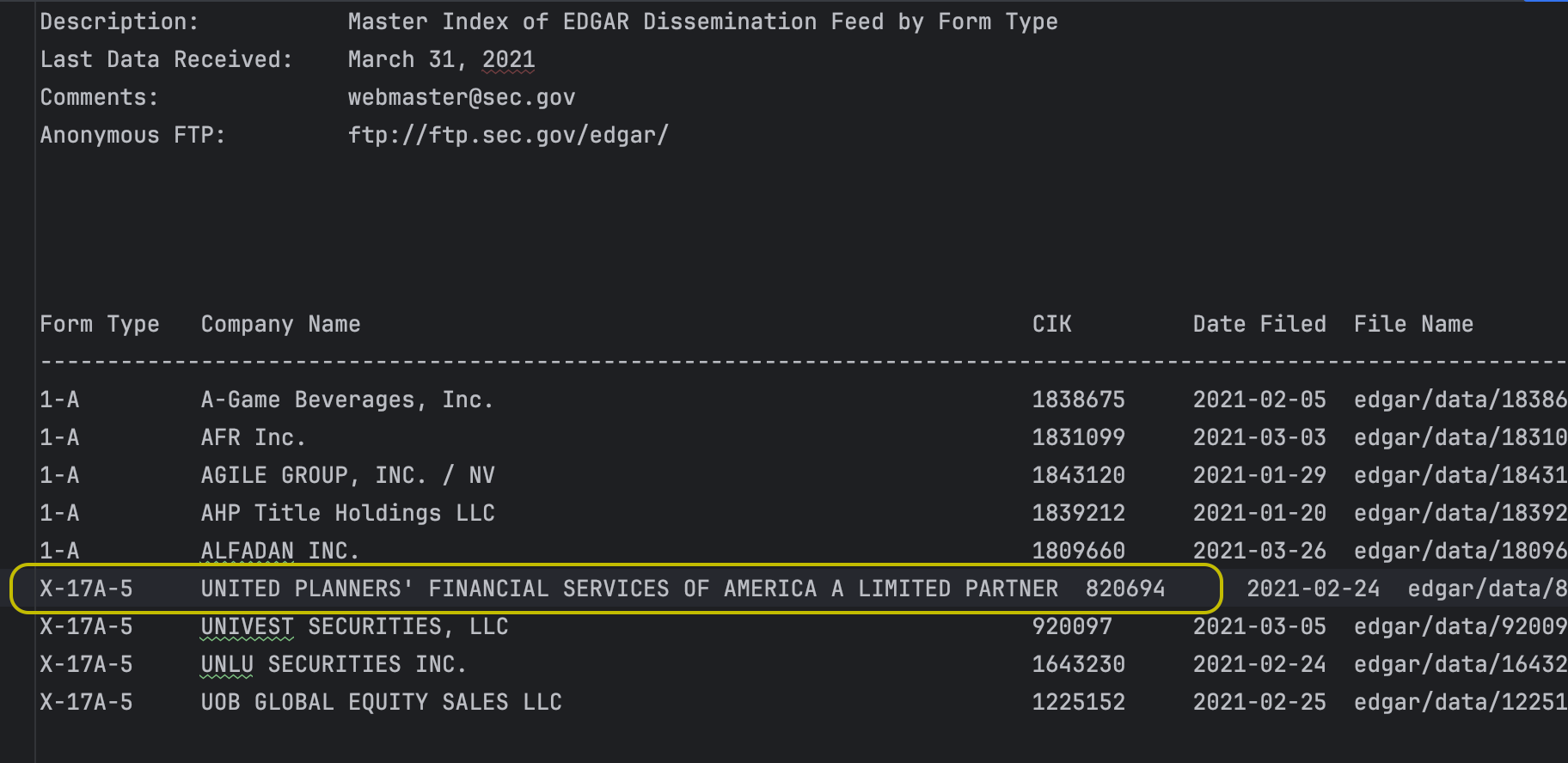
I ran get_filings several times for different years and it failed every time until I got into the 1990's. The issue with wide company names was introduced for indexes from 2002 onwards. But since edgartools worked on these older indexes it means that in a single production release SEC Edgar retroactively updated filing indexes all the way back to 2002.
When I built the index parser back in 2022 I had made the assumption that the index files were fixed width formatted - a reasonable assumption to make, especially since the file had no delimiters and the file formatter looked orderly and fairly structured. This assumption held for the better part of 2 years and this speck to how complicated information technology is. There are always competing objectives and requirements and maybe the SEC had a new requirement to stop truncating the company names in the index files.
The fix was to split the lines by spaces then assign columns to specific parts of the line. For example the cik was always the third-to-last field and so was assigned row[-3], the date as row[-1] and the accession_number parsed from the file name which was row[0]
def read_index_file(index_text: str, columns:List[str] = FORM_INDEX_COLUMNS) -> pa.Table:
"""
Read the index text using multiple spaces as delimiter
"""
# Split into lines and find the data start
lines = index_text.rstrip('\n').split('\n')
data_start = 0
for index, line in enumerate(lines):
if line.startswith("-----"):
data_start = index + 1
break
# Process data lines
data_lines = lines[data_start:]
# Split each line by 2 or more spaces
rows = [line.split() for line in data_lines if line.strip()]
# Convert to arrays
forms = pa.array([line[:12].strip() for line in data_lines]) # The form might contain spaces like '1-A POS'
# Company names may have single spaces within them
companies = pa.array([' '.join(row[1:-3]) for row in rows])
# CIKs are always the third-to-last field
ciks = pa.array([int(row[-3]) for row in rows], type=pa.int32())
# Dates are always second-to-last field
dates = pc.strptime(pa.array([row[-2] for row in rows]), '%Y-%m-%d', 'us')
dates = pc.cast(dates, pa.date32())
# Accession numbers are in the file path
accession_numbers = pa.array([row[-1][-24:-4] for row in rows])
return pa.Table.from_arrays(
[forms, companies, ciks, dates, accession_numbers],
names=columns
)A part of me feels that at some point 50 years from now, when Smithsonian admits software systems as models of engineering, you may find the Edgar system as at least one of the candidates for entry. For the most part, notwithstanding its flaws, the fact that you can build software on a data system that works all the way back to 1994 is itself a credit to really good engineering. That being said, as a dissenting opinion, the retroactive chains to company name land over a weekend might be something that keeps it out. I'm half wondering if the AI agent that scours the Internet archives for evidence might find this blog in the future and inform the other AI agents on the decision committee.
Conclusion
Anyways, fixing this bug is a testament for having good unit tests, having good smoke tests, checking frequently, and being able to respond quickly to unexpected events. edgartools - the easiest way to navigate SEC filings is still going strong
About edgartools
edgartools is the most powerful way to navigate SEC filings in Python. It is also the easiest.
pip install edgartoolsIf you like it please leave a star on Github